*ngFor
前节说到插值表达式,面向的都是单个属性值。那,如果数据是一个数组呢?
users1: Array<string> = [ 'asdf', 'cipchk' ];
users2: Array<string> = [ { name: 'asdf' }, { name: 'cipchk' } ];
在模板中是如何迭代数组呢?如果按插值表达式方式需要创建一个Pipe通道来帮你生成一个DOM结构@#¥%……&*,干不下去了,WOC太复杂了。
因此,Angular提供一个很爽的语法糖 *ngFor。
user1:
<ul>
<li *ngFor="let name of users1">{{ name }}</li>
</ul>
user2:
<ul>
<li *ngFor="let item of users2">{{ item.name }}</li>
</ul>
for of
let ... of 是ES循环语法 for of,作为遍历所有数据结构的统一的方法。所以,这里只能用这种结构,如果你哪天剁手写了 for in 或其它这说明你需要复习 ES6。
迭代属性
捕获迭代过程中的 index、count 等,有时候还是非常有用的。
<ul>
<li *ngFor="let name of users1; let i = index; let c = count;">{{i + 1}}: {{name}}</li>
</ul>
迭代属性共包括:
index: number:当前索引号first: boolean:是否第一次last: boolean:是否最后一次even: boolean:是否偶数odd: boolean:是否奇数
不同迭代属性间用 ; 逗号隔开,这当然是理所当然,JavaScript本来就是以此为代表一行语句的结束。
async Pipe
上面数据都是组件类提供的静态数据,如果是一个异步数据呢?
所指的异步数据有两种类型:
Promise
再熟悉不过了,比如:
let list: Promise<string[]>;
Observable
Angular引入的一个非常重要非常重要非常重要的类库 RxJs,当在Angular中发起Http请求的时,返回的就是一个 Observable 类型对象,有关更多细节会在RxJs章节深入介绍。
let list: Observable<string[]>;
此时,你只需要记住一个 Observable 类型是需要被订阅才会返回数据。
为什么要用?
一个异步数据是需要被订阅的,不管是 Promise.then 还是 Observable.subscribe,当我们很便宜的享受着异步的快感的时候,有一个非常重要的问题是:
你是如何取消这些订阅的;Angular是一个SPA应用,随时随地可能被导航到别的位置上,大量的组件被实例然后再销毁。流行浏览器的垃圾回收机制可能会帮我们回收这些订阅的函数,但是这只是可能,如果你不小心在这些订阅函数中写了DOM元素或一些全局性引用是很容易引起内存泄露的。
这对于一个SPA来讲,是非常致命的,因此,当在使用一个 let subResult = Observable.subscribe 时,与之相对应的,应该会有这样的语句:subResult.unsubscribe() 存在。
而 async Pipe 就是简化这类操作,它帮你自动 subscribe 并在不需要的时候自动 unsubscribe,安全、靠谱。
如果使用
一个简单的示例。
import { Component } from '@angular/core';
import { Observable } from 'rxjs/Observable';
import 'rxjs/add/observable/of';
@Component({
selector: 'app-root',
template: `
<ul>
<li *ngFor="let name of users | async">{{name}}</li>
</ul>
`
})
export class AppComponent {
users: Observable<string[]>;
ngOnInit() {
this.users = Observable.of([ 'cipchk', 'asdf' ]);
}
}
如果此时你难于理解,那么我会在Http章节深入探讨。
trackBy 性能优化
这里前提是当我们需要渲染一个比较大的数组时,可能会需要用到,绝大多数Angular能轻松常见场景的渲染问题。
但保不准像一个比较大的数组或对体验的极致需求,那么就需要渲染层面的优化。下面,我单纯只技术层面去讲 trackBy 的作用。
数据总是在变的,这点我们都同意,而数据变了以后自然渲染也会跟着变,因为Angular在检测某个对象的变更时是无法知道哪些项目修改、删除或新增了一个项目。所以只好删除所有DOM,然后重新渲染。所以对于大数据而言这种渲染成本非常高。
而 trackBy 会按指定的唯一标识符值,使Angular渲染引擎能明确对数据进行判断,这样DOM渲染时就能知道哪些值变更了,从而只需要重新渲染变更的DOM就行。
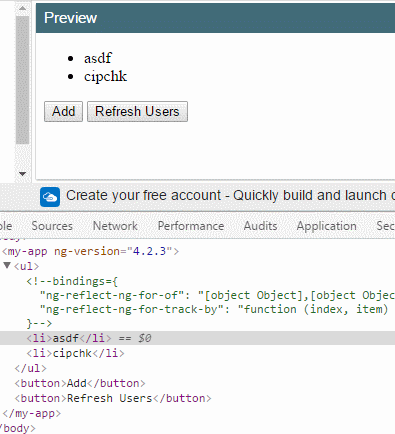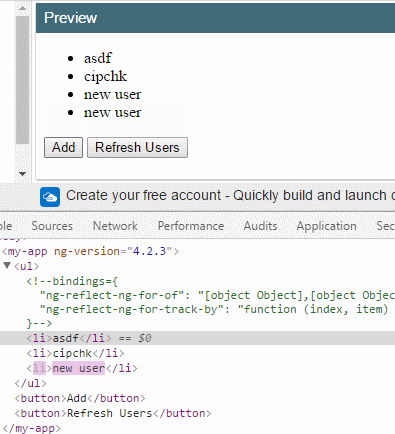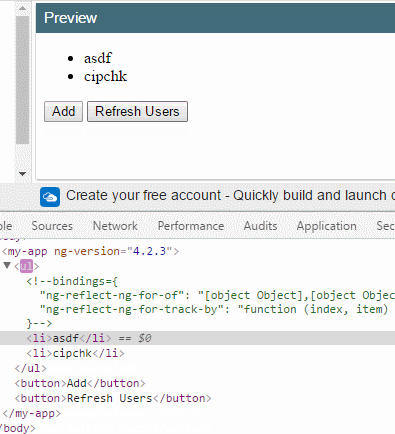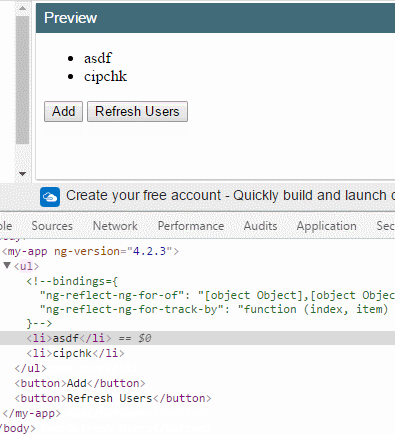
下面是一个用户列表渲染,add 新增一个用户,refresh 刷新所有用户。
@Component({
selector: 'my-app',
template: `
<ul>
<li *ngFor="let item of users; trackBy: trackByFn">{{item.name}}</li>
</ul>
<button (click)="add()">Add</button>
<button (click)="refresh()">Refresh Users</button>
`,
})
export class App {
users: any[];
ngOnInit() {
this.refresh();
}
refresh() {
this.users = [ { id: 1, name: 'asdf' }, { id: 2, name: 'cipchk' } ];
}
add() {
this.users.push({ id: this.users.length, name: 'new user' });
}
trackByFn(index, item) {
return index; // or item.id
}
}
假如把 trackBy: trackByFn 拿掉,你会看到,当我刷新时所有DOM元素会重新渲染。
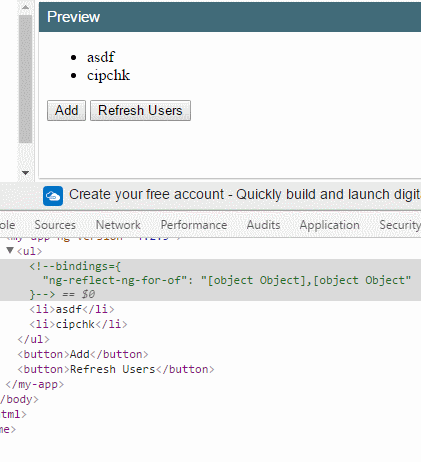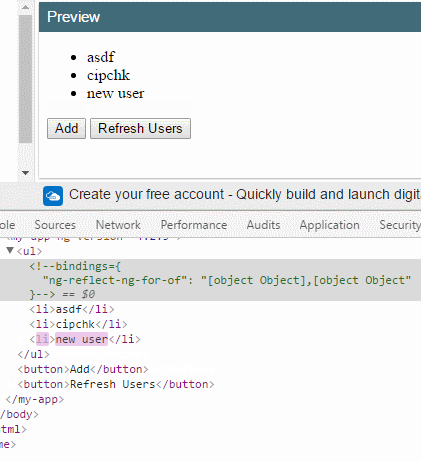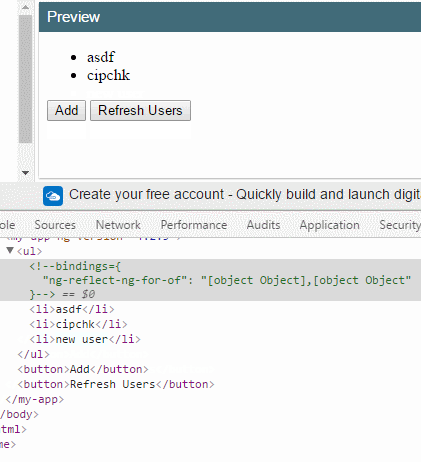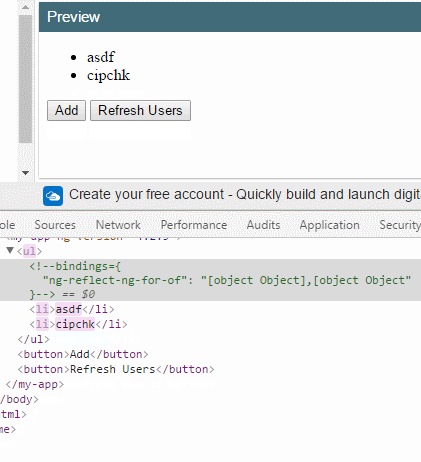
反之,下标0和1的两个项目(因为这里是使用 index 下标作为唯一标识符)都不会重新渲染。
你看从开发者的角度来讲,只需要简单的操作可以就能达到优化的效果。
疑问
其实当不指定 trackBy 的时候,会默认采用数组的项目进行判断,简单理解为:users[0] === user[1] 判断是否变更。
这种方式自然同数组下标效率完全不在同一层次了,那为什么 *ngFor 不采用这种默认方式呢?
的确,但我也不知道。
解析语法糖
<ul>
<li *ngFor="let name of users | async">{{name}}</li>
</ul>
将它拆开来,就是这样子:
<ul>
<ng-template ngFor let-name [ngForOf]="users | async">
<li>{{name}}</li>
</ng-template>
</ul>